Basic Usage
In Quick Start article, we introduced opentenbase architecture, source code compilation and installation, cluster running status, startup and stop, etc.
This article will introduce the creation of shard table, replication table and basic DML operation in opentenbase.
1、Create table
1.1、Create shard table
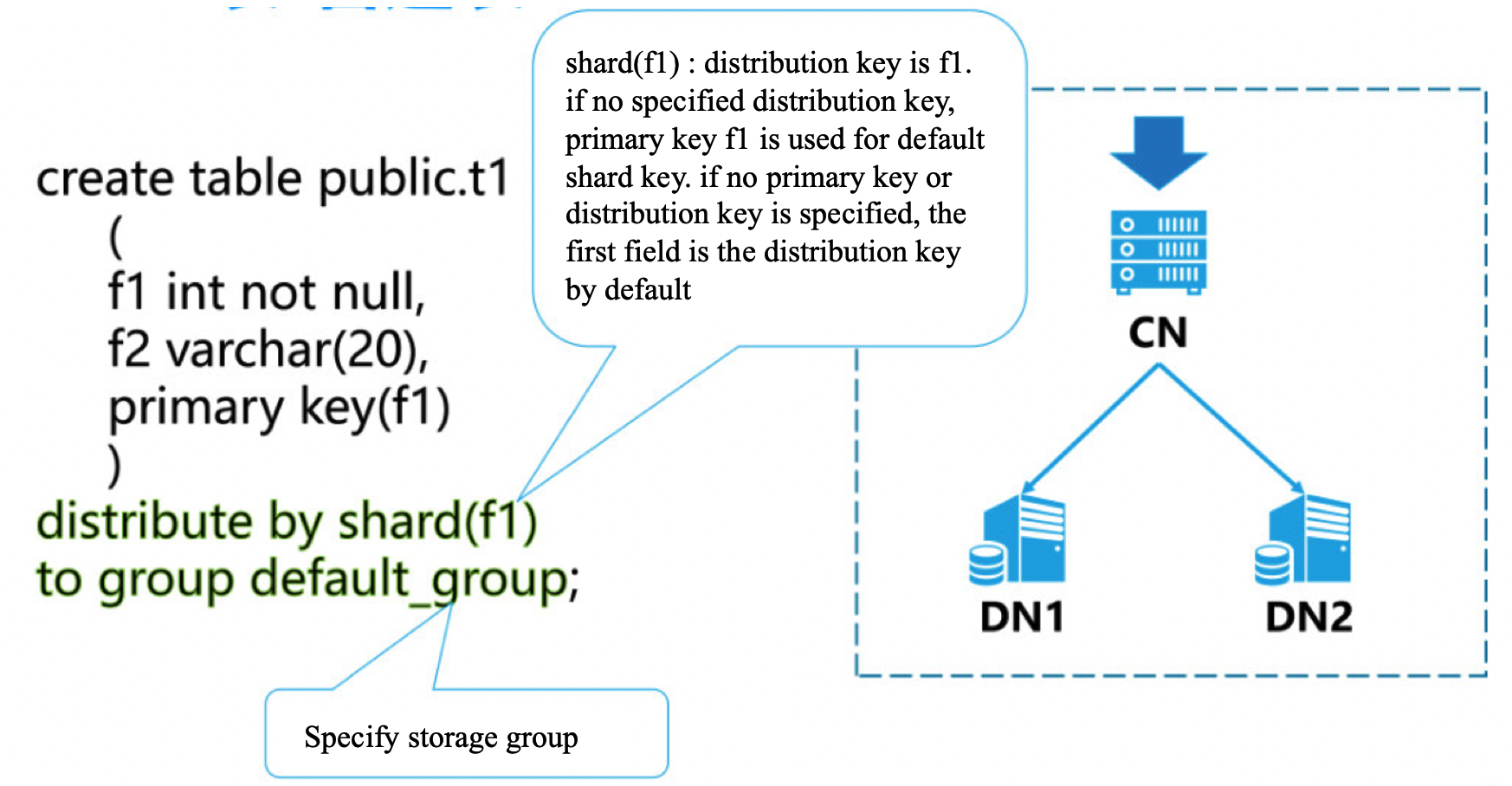
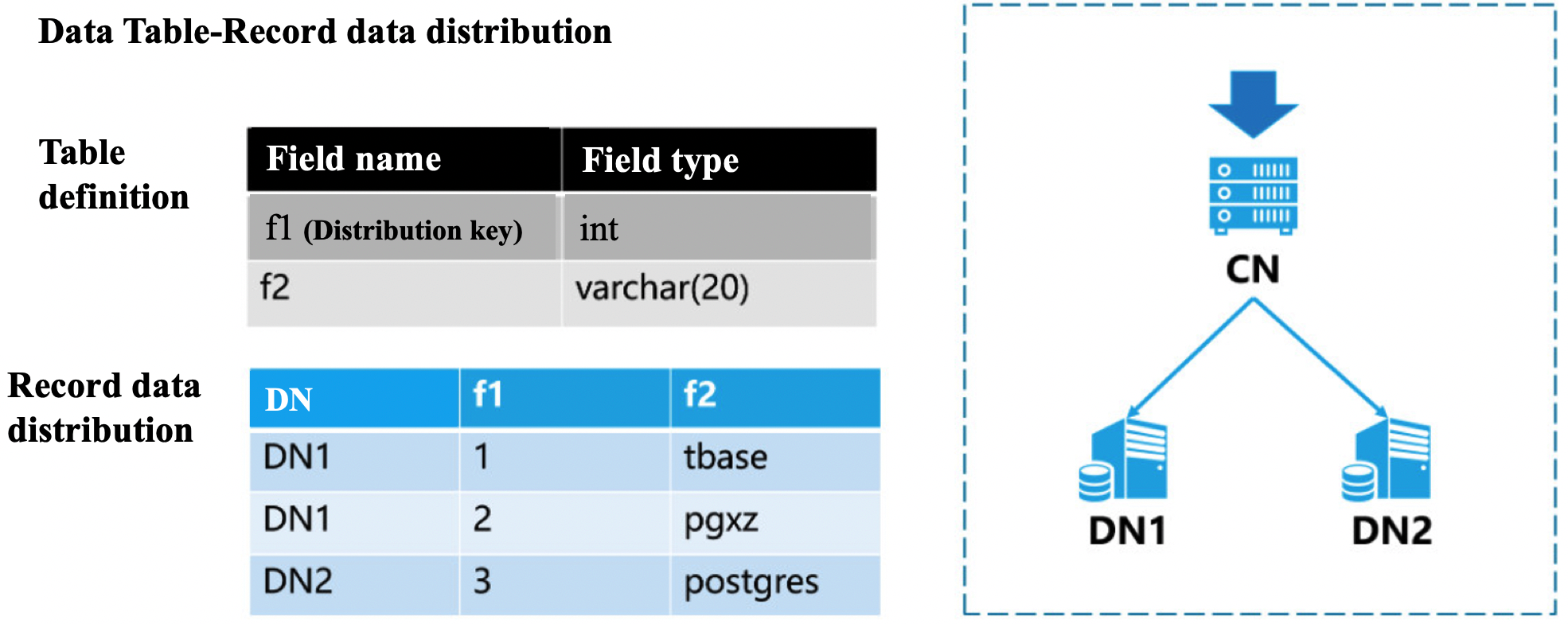
 Explain:
Explain:
- distribute by shard (x) is used to specify the distribution key. Based on the value of this field, calculate which node the partition data is distributed to .
- to group XXX is used to specify storage groups (each storage group can have multiple nodes).
- distribution key field value cannot be modified, field length cannot be modified, and field type cannot be modified.
1.2、Create partition shard table
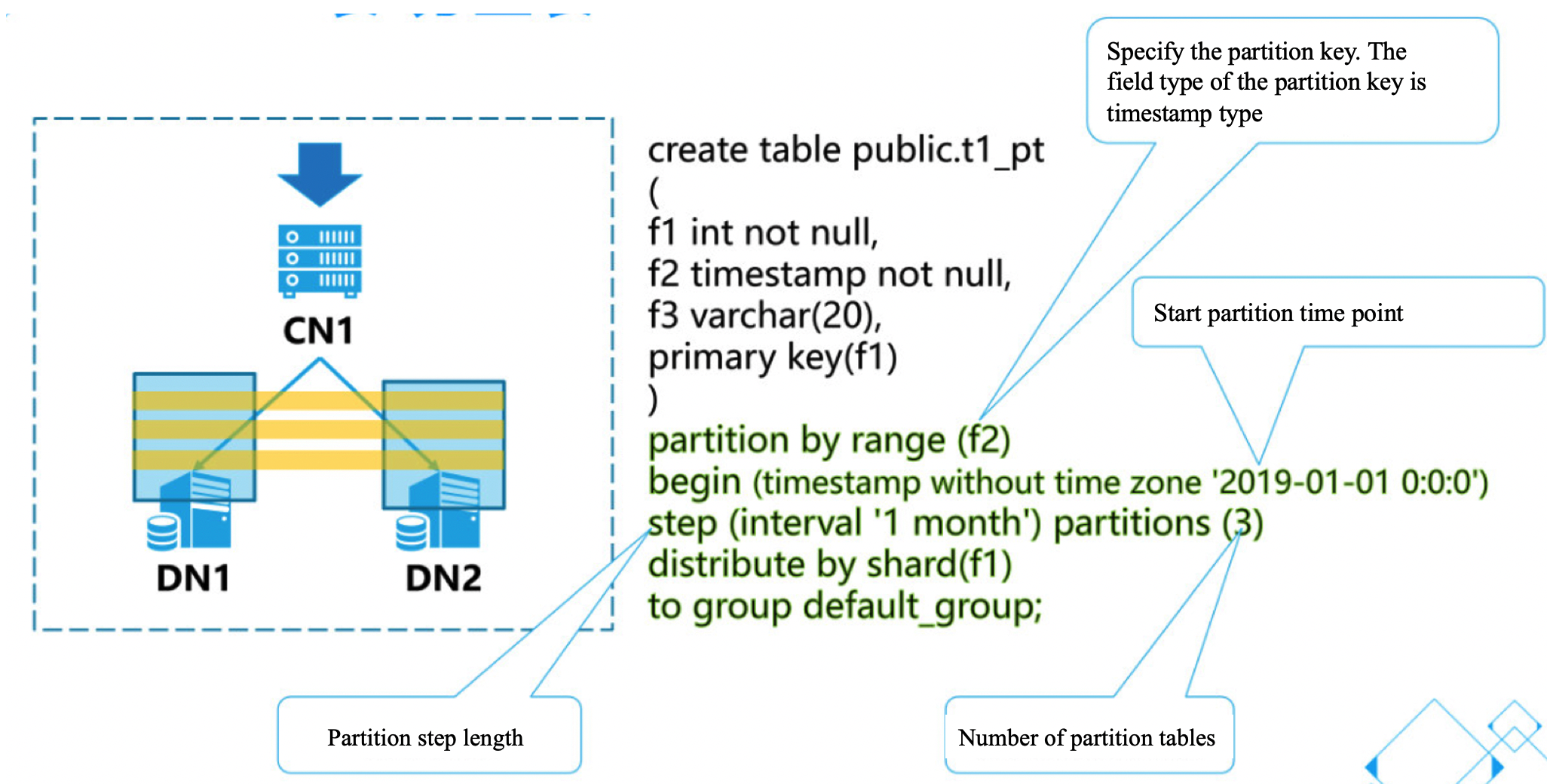
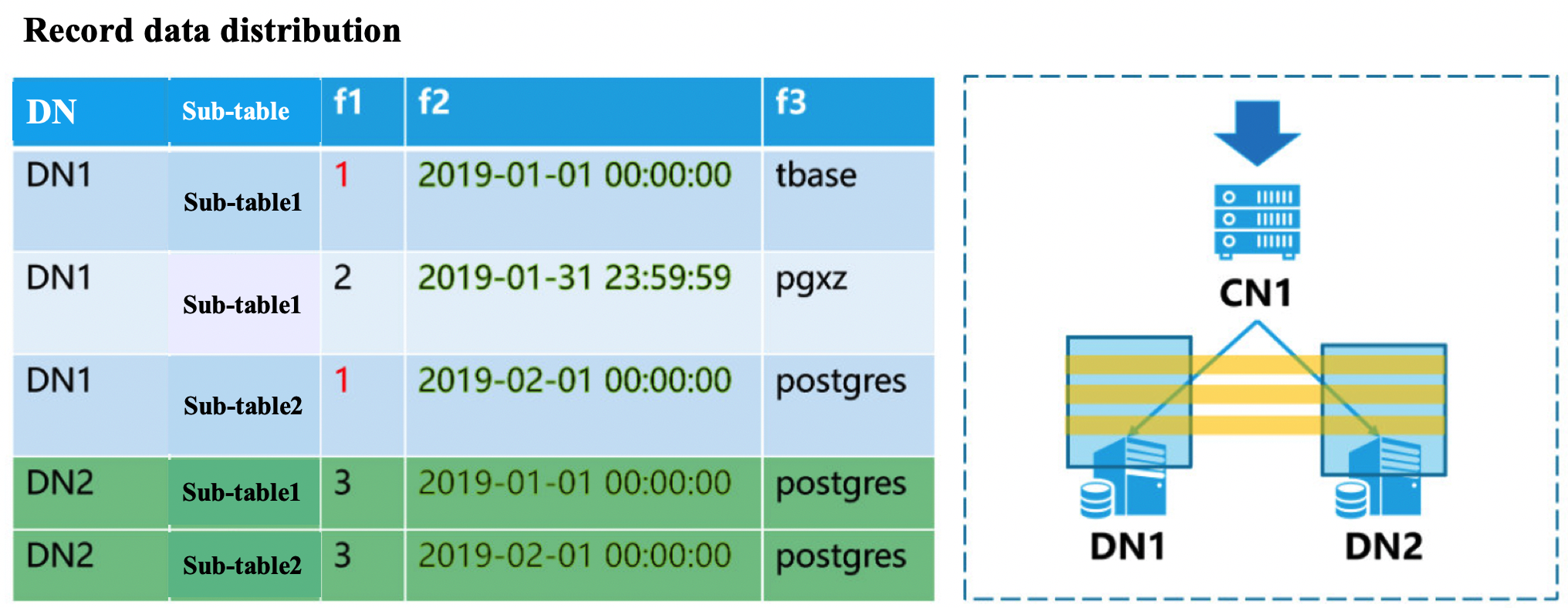
[opentenbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11387 -d postgres -U opentenbase
psql (PostgreSQL 10.0 opentenbase V2)
Type "help" for help.
postgres=# create table public.t1_pt
(
f1 int not null,
f2 timestamp not null,
f3 varchar(20),
primary key(f1)
)
partition by range (f2)
begin (timestamp without time zone '2019-01-01 0:0:0')
step (interval '1 month') partitions (3)
distribute by shard(f1)
to group default_group;
CREATE TABLE
postgres=#
postgres=# \d+ public.t1_pt
Table "public.t1_pt"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
f1 | integer | | not null | | plain | |
f2 | timestamp without time zone | | not null | | plain | |
f3 | character varying(20) | | | | extended | |
Indexes:
"t1_pt_pkey" PRIMARY KEY, btree (f1)
Distribute By: SHARD(f1)
Location Nodes: ALL DATANODES
Partition By: RANGE(f2)
# Of Partitions: 3
Start With: 2019-01-01
Interval Of Partition: 1 MONTH
postgres=#
Explain:
- partition by range (x) is used to specify the partition key. It supports the type of timesamp and int. according to this field value, it calculates which sub table the partition data is distributed in.
- begin( xxx ) is used to specifies the time point to start the partition。
- step(xxx) is used to specified partition has period
- partions(xx) is used to establish the number of partition sub tables during initialization.
- Method of adding partition sub table: ALTER TABLE public.t1_pt ADD PARTITIONS 2;
1.3、Create repilication table
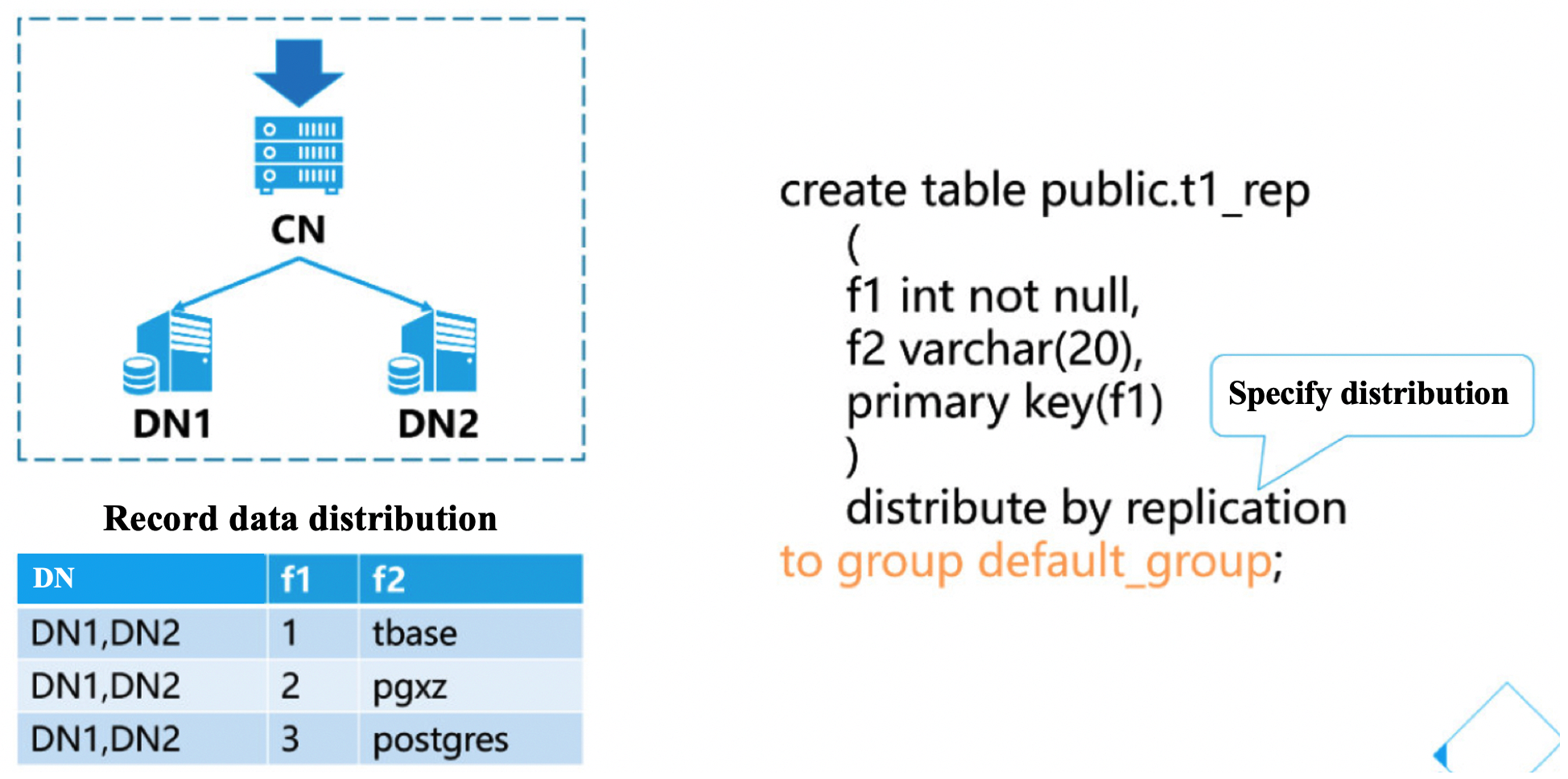
[opentenbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11387 -d postgres -U opentenbase
psql (PostgreSQL 10.0 opentenbase V2)
Type "help" for help.
postgres=# create table public.t1_rep
(
f1 int not null,
f2 varchar(20),
primary key(f1)
)
distribute by replication ;
to group default_group;
CREATE TABLE
Explain:
- Replication tables can be considered for small data scales that often need to join across nodes
- Replication table means that every DN has full data, which is not suitable for large data tables.
- Replication table update performance is low.
2、DML related operations
2.1、INSERT
- Insert multiple records
CREATE TABLE public.t1_insert_mul
(
f1 int not null,
f2 varchar(20),
primary key(f1)
) distribute by shard(f1) to group default_group;
postgres=# INSERT INTO t1_insert_mul VALUES(1,'opentenbase'),(2,'pg');
INSERT 0 2
- Insert for updating
create table public.t1_conflict
(
f1 int not null,
f2 varchar(20),
primary key(f1)
) distribute by shard(f1) to group default_group;
insert into t1_conflict values(1,'opentenbase') ON CONFLICT (f1) DO UPDATE SET f2 = 'opentenbase';
create table public.t1_conflict
(
f1 int not null,
f2 varchar(20) not null,
f3 int ,
primary key(f1,f2)
) distribute by shard(f1) to group default_group;
insert into t1_conflict values(1,'opentenbase',2) ON CONFLICT (f1,f2) DO UPDATE SET f3 = 2;
- Insert for returning
create table public.t1_insert_return
(
f1 int not null,
f2 varchar(20) not null default 'opentenbase',
primary key(f1)
) distribute by shard(f1) to group default_group;
postgres=# insert into t1_insert_return values(1) returning *;
f1 | f2
----+-------
1 | opentenbase
(1 row)
INSERT 0 1
- For more usage of insert, please refer to PostgreSQL usage
http://www.postgres.cn/docs/10/sql-insert.html
2.2、UPDATE
- Update based on distribution key condition
create table public.t1_update_pkey
(
f1 int not null,
f2 varchar(20) not null default 'opentenbase',
f3 varchar(32),
primary key(f1)
) distribute by shard(f1) to group default_group;
postgres=# explain UPDATE t1_update_pkey SET f2='opentenbase' where f1=1;
QUERY PLAN
----------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Update on t1_update_pkey (cost=0.15..4.17 rows=1 width=154)
-> Index Scan using t1_update_pkey_pkey on t1_update_pkey (cost=0.15..4.17 rows=1 width=154)
Index Cond: (f1 = 1)
Best performance, good scalability
- Update based on non-distribution key condition
postgres=# explain UPDATE t1_update_pkey SET f2='opentenbase' where f3='pg'; QUERY PLAN
----------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Update on t1_update_pkey (cost=0.00..15.12 rows=2 width=154)
-> Seq Scan on t1_update_pkey (cost=0.00..15.12 rows=2 width=154)
Filter: ((f3)::text = 'pg'::text)
(5 rows)
UPDATE statement will send to all nodes.
- Update partition table based on partition condition
create table public.t1_pt_update
( f1 int not null,f2 timestamp not null,f3 varchar(20),primary key(f1) )
partition by range (f2) begin (timestamp without time zone '2019-01-01 0:0:0') step (interval '1 month') partitions (2) distribute by shard(f1) to group default_group;
postgres=# explain update t1_pt_update set f3='opentenbase' where f1=1 and f2>'2019-01-01' and f2<'2019-02-01'; QUERY PLAN
-----------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Update on t1_pt_update_part_0 (cost=0.15..4.17 rows=1 width=80)
-> Index Scan using t1_pt_update_pkey_part_0 on t1_pt_update_part_0 (cost=0.15..4.17 rows=1 width=80)
Index Cond: (f1 = 1)
Filter: ((f2 > '2019-01-01 00:00:00'::timestamp without time zone) AND (f2 < '2019-02-01 00:00:00'::timestamp without time zone))
Update based on partition condition,best performance, good scalability
- Update partition table without partition condition
postgres=# explain update t1_pt_update set f3='opentenbase' where f1=1; QUERY PLAN
------------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Update on t1_pt_update (cost=0.15..4.17 rows=1 width=80)
-> Index Scan using t1_pt_update_pkey_part_0 on t1_pt_update (partition sequence: 0, name: t1_pt_update_part_0) (cost=0.15..2.08 rows=0 width=80)
Index Cond: (f1 = 1)
-> Index Scan using t1_pt_update_pkey_part_1 on t1_pt_update (partition sequence: 1, name: t1_pt_update_part_1) (cost=0.15..2.08 rows=0 width=80)
Index Cond: (f1 = 1)
(7 rows)
All partition sub tables need to be scanned
- Table association update
create table public.t1_update_join1
(
f1 int not null,f2 varchar(20) not null default 'opentenbase',primary key(f1)
)
distribute by shard(f1) to group default_group;
create table public.t1_update_join2
(
f1 int not null,f2 varchar(20) not null default 'opentenbase',primary key(f1)
)
distribute by shard(f1) to group default_group;
update t1_update_join1 set f2='pg' from t1_update_join2 where t1_update_join1.f1=t1_update_join2.f1;
Table Association updates can only be based on distribution key associations
- Distribution key, partition key cannot be updated
create table public.t1_update_pkey
(
f1 int not null,f2 varchar(20) not null default 'opentenbase', primary key(f1)
) distribute by shard(f1) to group default_group;
postgres=# update t1_update_pkey set f1=2 where f1=1;
ERROR: Distributed column or partition column "f1" can't be updated in current version
Time: 0.910 ms.
The current solution is "delete old records and add new records"
- Please refer to PostgreSQL for more usage of UPDATE
http://www.postgres.cn/docs/10/sql-update.html
2.3、DELETE
- Return deleted records when deleting
create table public.t1_delete_return
(
f1 int not null,f2 varchar(20) not null default 'opentenbase',primary key(f1)
)
distribute by shard(f1) to group default_group;
postgres=# insert into t1_delete_return values(1,'opentenbase');
INSERT 0 1
postgres=# delete from t1_delete_return where f1=1 returning *;
f1 | f2
----+-------
1 | opentenbase
(1 row)
-
The optimal usage of update is also suitable for delete
-
Please refer to PostgreSQL for more usage of DELETE
http://www.postgres.cn/docs/10/sql-delete.html
2.4、SELECT
- Select based on distributed key
create table public.t1_select
(
f1 int not null,f2 varchar(20) not null default 'opentenbase',f3 varchar(32), primary key(f1)
)
distribute by shard(f1) to group default_group;
postgres=# explain select * from t1_select where f1=1; QUERY PLAN
----------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Index Scan using t1_select_pkey on t1_select (cost=0.15..4.17 rows=1 width=144)
Index Cond: (f1 = 1)
best performance, good scalability
- Select based on non-distributed key
postgres=# explain select * from t1_select where f1<3;
QUERY PLAN
-------------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001, dn002
-> Bitmap Heap Scan on t1_select (cost=3.21..14.92 rows=137 width=144)
Recheck Cond: (f1 < 3)
-> Bitmap Index Scan on t1_select_pkey (cost=0.00..3.17 rows=137 width=0)
Index Cond: (f1 < 3)
The query statement will be sent to all nodes and then summarized in CN.
- Join query based on distributed key
create table public.t1_select_join1
( f1 int not null,f2 int,primary key(f1) )
distribute by shard(f1) to group default_group;
create index t1_select_join1_f2_idx on t1_select_join1(f2);
create table public.t1_select_join2
( f1 int not null,f2 int,primary key(f1) )
distribute by shard(f1) to group default_group;
create index t1_select_join2_f2_idx on t1_select_join2(f2);
postgres=# explain select t1_select_join1.* from t1_select_join1,t1_select_join2 where t1_select_join1.f1=t1_select_join2.f1 and t1_select_join1.f1=1;
QUERY PLAN --------------------------------------------------------------------------------------
Remote Fast Query Execution (cost=0.00..0.00 rows=0 width=0)
Node/s: dn001
-> Nested Loop (cost=0.30..8.35 rows=1 width=8)
-> Index Scan using t1_select_join1_pkey on t1_select_join1 (cost=0.15..4.17 rows=1 width=8)
Index Cond: (f1 = 1)
-> Index Only Scan using t1_select_join2_pkey on t1_select_join2 (cost=0.15..4.17 rows=1 width=4)
Index Cond: (f1 = 1)
best performance, good scalability
- Join query based on non-distributed key
postgres=# explain select * from t1_select_join1,t1_select_join2 where t1_select_join1.f1=t1_select_join2.f2 and t1_select_join1.f2=1 ;
QUERY PLAN ------------------------------------------------------------------------------------------
Remote Subquery Scan on all (dn001,dn002) (cost=2.26..33.48 rows=7 width=16)
-> Nested Loop (cost=2.26..33.48 rows=7 width=16)
-> Bitmap Heap Scan on t1_select_join1 (cost=2.13..9.57 rows=7 width=8) Recheck Cond: (f2 = 1)
-> Bitmap Index Scan on t1_select_join1_f2_idx (cost=0.00..2.13 rows=7 width=0)
Index Cond: (f2 = 1)
-> Materialize (cost=100.12..103.45 rows=7 width=8)
-> Remote Subquery Scan on all (dn001,dn002) (cost=100.12..103.44 rows=7 width=8)
Distribute results by S: f2
-> Index Scan using t1_select_join2_f2_idx on t1_select_join2 (cost=0.12..3.35 rows=7 width=8)
Index Cond: (f2 = t1_select_join1.f1)
Need to redistribute data in DN.
2.5、TRUNCATE
- Truncate of non-partition table
create table public.t1_delete_truncate
( f1 int not null,f2 varchar(20) not null default 'opentenbase',primary key(f1) )
distribute by shard(f1) to group default_group;
insert into t1_delete_truncate select t,t::text from generate_series(1,1000000) as t;
truncate table t1_delete_truncate;
- Truncate of partition table
postgres=# create table public.t1_pt
(
f1 int not null,
f2 timestamp not null,
f3 varchar(20),
primary key(f1)
)
partition by range (f2)
begin (timestamp without time zone '2019-01-01 0:0:0')
step (interval '1 month') partitions (3)
distribute by shard(f1)
to group default_group;
truncate public.t1_pt partition for ('2019-01-01' ::timestamp without time zone);